03 Select
SQL 문장 작성법
- SQL 문장은 대소문자를 구별하지 않습니다.
- SQL문장은한줄또는여러줄에입력될수있습니다.
- 하나의 명령어는 여러 줄에 나누거나 단축될 수 없습니다.
- 젃은 보통 읽고 편집하기 쉽게 줄을 나누도록 합니다.(권장)
- 탭과 줄 넣기(들여쓰기)는 코드를 보다 읽기 쉽게 하기 위해 사용됩니다.(권장)
- 일반적으로 키워드는 대문자로 입력합니다.
- 키워드를제외한다른모든단어,즉테이블이름,열이름은소문자로입력합니 다.(권장)
- SQL*Plus에서SQL 문장은 SQL 프롬프트에 입력되며 1라인 이후의 라인은 라인 번 호가 붙습니다. 가장 최근의 명령어가 1개가 SQL buffer에 저장됩니다.
SQL 문장 실행
- 마지막 젃의 끝에 “;”를 기술하여 명령의 끝을 표시
- 버퍼에서 마지막 라인에 슬래시를 넣습니다.(OS의 Editor사용시)
- SQL프롬프트에 슬래시를 입력합니다.(SQL Buffer의 내용 실행)
- SQL프롬프트에서 SQL*Plus RUN 명령어를 실행합니다. (SQL Buffer의 내용 실행)
SQL 기본 문장
SELECT : 원하는 컬럼을 선택
* : 테이블의 모든 column 출력
alias : 해당 column에 대한 다른 이름 부여
DISTINCT : 중복 행 제거 옵션
FROM : 원하는 데이터가 저장된 테이블 명을 기술.
WHERE : 조회되는 행을 제한(선택)
condition : column, 표현식, 상수 및 비교 연산자
ORDER BY : 정렬을 위한 옵션(ASC:오름차순(Default),DESC내림차순)
기본 형식
select 원하는column이름 from table이름 ;
EX
select * from emp;
>> emp 테이블의 모든 칼럼을 선택
select empno, ename, job, deptno from emp;
>> emp 테이블에서 직원 코드, 직원 이름, 직업(업무), 부서 코드를 선택
where 조건과 비교 연산자
원하는 로우만 얻으려면 다음과 같이 로우를 제한하는 조건을 SELECT 문에 WHERE 절을 추가하여 제시해야합니다.
조건절의 구성 = 칼럼 + 연산자 + 비교대상자
Select column from table_name where 조건절 ;
EX
select ename, sal from emp where sal>3000 ;
>> emp 테이블에서 sal 이 3000을 초과하는 직원의 이름과 임금
select ename, sal from emp where sal<=3000 ;
>> emp 테이블에서 sal 이 3000이하인 직원의 이름과 임금
select ename, sal, hiredate from emp where hiredate>='82/01/01' ;
>> emp 테이블에서 입사일이 82년01월01일 이후에 해당하는 직원의 이름, 임금, 입사일
select * from emp where deptno=10 ;
>> emp 테이블에서 부서코드가 10인 모든 칼럼
-- describe table
desc emp;
-- * 는 모든 column
select * from emp;
-- 문자는 작은 따옴표(' ')로 감싼다. 대소문자 구별한다.
select ename, job, sal from emp where job='ANALYST';
desc emp;
select * from tabb;
select * from emp where sal>=2000;
select * from emp where sal>=2000 and job='MANAGER';
select * from emp where sal<1500 and job='ANALYST';
select ename, job, deptno from emp where deptno!=10;
select ename, job, deptno from emp where job='MANAGER' or job='SALESMAN';
select ename, job, deptno from emp where job!='SALESMAN' or sal>=2000;
select ename, job, comm, deptno, hiredate from emp where comm=300;
select empno, ename, job, hiredate, deptno from emp where hiredate>='82/01/01' and hiredate<='82/12/31';
LITERAL 문자 STRING
- LITERAL은 열 이름이나 열 별칭이 아닌 SELECT목록에 포함되어
- 있는 문자, 표현식, 숫자
- RETURN되는 각각의 행에 대해 출력됩니다.
- LITERAL과 STRING은 질의 결과에 포함될 수 있으며 SELECT목 록에서 열과 똑같이 취급됩니다.
- 날짜와 문자 LITERAL은 단일 인용 부호(„ „)를 사용하여야 하고 숫자 LITERAL은 사용하지 않습니다.
- SELECT젃에 포함된 LITERAL은 문자, 표현식, 숫자입니다.
- 날짜와 문자 LITERAL 값은 단일 인용부호(„ „) 안에 있어야 합니 다.
- 각각의 문자 STRING은 RETURN된 각 행에 대한 결과입니다.
작은 따옴표 (' ')
EX
select * from emp where ename='MILLER' ;
>> emp 테이블에서 이름이 MILLER인 모든 칼럼
논리 연산자
오라클에서 사용 가능한 논리 연산자 AND나 OR나 NOT가 있습니다.
(사용은 자바와 비슷)

논리 연산자
1. NOT 연산자는 BETWEEN, LIKE, IS NULL과 같은 다른 SQL연산자와 함께 사용
2. EMP 테이블에서 job이 MANAGER, CLERK, ANALYST가 아닌 사원의 empno,ename,job,sal,deptno를 출력
SELECT empno,ename,job,sal,deptno FROM emp
WHERE job NOT IN ('MANAGER','CLERK','ANALYST')
EX
select * from emp where sal between 2000 and 3000 ;
>> emp 테이블에서 급여가 2000 이상 3000이하인 로우의 모든 칼럼
select * from emp where comm is null ;
>> emp 테이블에서 커미션이 null 인 로우의 모든 칼럼
select ename, sal, comm from emp where comm is not null ;
>> emp 테이블에서 커미션이 null이 아닌 로우의 모든 칼럼
select * from emp where ename like "M%" ;
>> emp 테이블에서 이름이 M으로 시작하는 로우의 모든 칼럼
select * from emp where ename like "M%" ;
>> emp 테이블에서 이름이 M으로 시작하는 로우의 모든 칼럼
산술 표현식
주의
- 계산된 결과 열SAL+300은 EMP테이블의 새로운 열이 아니고 단지 디스플레 이를 위한 것
- 디폴트로 새로운 열의 이름 sal+300은 생성된 계산식으로부터 유래
- SQL*Plus는 산술 연산자 앞뒤의 공백을 무시
null값의 처리
- 행이특정열에대한데이터값이없다면값은null
- null값은이용할수없거나지정되지않았거나,알수없거나또는적용할수 없는 값
- null값은 0이나 공백과는 다르며 0은 숫자이며 공백은 문자
- 열이 NOT NULL로 정의되지 않았거나 열이 생성될 때 PRIMARY KEY로 정의 되지 않았다면 열은 null값을 포함
- EMP 테이블의 COMM열에서 오직 SALESMAN맊이 보너스를 받을 수 있음
- 널값을포함한산술표현식결과는NULL
- column에데이터값이없으면그값자체가널또는널값을포함
- 널 값은 1바이트의 내부 저장 장치를 오버헤드로 사용하고 있으며 어떠한 datatype column들이라도 널 값을 포함
Null 값
NULL이란 이용 불가능한(Unavailable), 지정되지 않은(Unassigned), 알 수 없는 (Unknown),적용할 수 없는(Inapplicable)값을 의미
한 가지 기억해야 할 것은 NULL은 0(Zero) 또는 공백(Space)과는 다르다 아래 SQL 문장을 수행해보면 값 이 표시되지 않는 데이터가 NULL이다.
Ex
select * from emp;
select ename, sla, sal+100, sal*2 from emp;
-- java에서 null = 값이 없다 변수 == 값이 가능
-- DB에서는 null = 알 수 없다/사용할 수 없다 ( 즉 =으로 비교할 수 없고 is 또는 is not )
select ename, job, sal, comm from emp where comm=null;됨 -- 이건 안 됨
select ename, job, sal, comm from emp where comm is null;
select ename, job, sal, comm from emp where comm!=null; -- 이건 안 됨
select ename, job, sal, comm from emp where comm is not null;
NVL 함수
1. null값을 특정한 값(실제 값)으로 변환하는데 사용
2. 사용될수있는데이터타입은날짜,문자,숫자
3. NVL함수를사용할때젂환되는값의데이터타입을일치
NVL 1 함수 형식
nvl ( column , null일때 )e.g.
salary+commision
sal + comm if comm is null, comm=0
sal + nvl(comm,0)
다양한 데이터형에 대한 NVL변형
데이터형
NUMBER NVL(comm, 0)
DATE NVL(hiredate, „01-JAN-99‟)
CHAR or VARCHAR2 NVL(job, „업무없음‟)
NVL 2 함수 형식
nvl2 ( null값이 있는 column , null이 아닐 경우 , null일 경우 )e.g.
salary+commision : if comm is not null, (sal+com) / if comm is null, (sal)
nvl2 ( comm, sal+comm, sal)
Coalesce 형식 (mysql도 사용 가능)
coalesce ( null이 아닐 경우, null일 경우 )e.g.
salary+commision : if comm is not null, (sal+com) / if comm is null, (sal)
coalesce ( sal+comm, sal )
Ex
-- null 어떻게 값으로 처리할 것인가 ?
select ename, sal, comm, sal+comm from emp;
select ename, sal, comm, sal+nvl(comm,0), sal+nvl(comm,100) from emp;
-- sal+nvl(comm,0) : if comm is null, then comm = 0
-- nvl2(comm, sal+comm, sal) : if comm is not null, sal+comm / if null sal
-- coalesce(sal+comm, sal) coalesce 앞에서 부터 null이 아닐때까지 다음 행 실행
-- if not null => sal+comm
-- if null => sal
select ename, sal, comm, sal+nvl(comm,0), nvl2(comm,comm+sal, sal),
coalesce(sal+comm,sal) from emp;
select ename as "name", sal "salary", comm, sal+nvl(comm,0) salaryTotal,
nvl2(comm,comm+sal, sal), coalesce(sal+comm,sal) from emp;
----- 연습문제 -----
select ename, sal, comm, sal+nvl(comm,0), nvl2(comm,comm+sal, sal), coalesce(sal+comm,sal) from emp;
select ename, sal, comm, (sal+nvl(comm,0))*12 from emp;
select ename, sal, comm from emp where hiredate>='81/01/01' and hiredate<='81/12/31' and job='MANAGER';
select sal+nvl(comm,0) as "salary+bonus" from emp where comm is null;
select ename, sal, comm, (sal+nvl(comm,0))*12 "연봉" from emp where comm is not null and sal>=1500;
select ename "이름", sal "급여", deptno "부서코드" from emp where deptno=10 or job='MANAGER';
select ename, sal, comm, nvl2(comm,comm+sal,sal) "실급여" from emp where sal<=1500 or job='CLERK';
별칭(Alias)
열에 별칭(Alias) 부여
- 질의의 결과를 출력할 때 SQL*Plus는 열 Heading으로 선택된 열 이름을 사용
- 이 Heading은 때로 사용자가 이해하기가 어려운 경우가 있기 때문에 열 Heading을 변경하여 질의 결과를 출력하면 보다 사용자가 이해
열 별칭(Alias) 정의
- 열 Heading이름을 변경 합니다.
- 계산에 유용합니다.
- 열이름바로뒤에사용합니다.
- 열이름과별칭사이에키워드AS를넣기도합니다.
- 공백이나 특수 문자 또는 대문자가 있으면 이중 인용부호(“ ”)가 필요 합니 다.
e.g.
sql> SELECT ename AS 이름, sal 급여 FROM emp
EMP 테이블에서 ENAME를 이름으로 SAL을 급여로 출력
sql> SELECT ename, sal+nvl(comm,0) "급여 합" FROM emp
만약 별칭이 한글자가 아니라면 큰따옴표 사용 (" ")
연결연산자
- 연결 연산자(||)를 사용하여 문자 표현식을 생성하기 위해 다른 열, 산술 표현식, 상수 값에 열을 연결 할 수 있습니다.
- 연결자의왼쪽에있는열은단일결과열을맊들기위해조 합 됩니다.
- 열이나 문자 STRING을 다른 열에 연결 합니다.
- 두 개의 “||”로 연결 합니다.
- 문자 표현식의 결과 열을 생성 합니다.
e.g.
sql> SELECT ename || ' ' || job AS "employees“ FROM emp
EMP 테이블에서 ename과 job을 묶어서 employees로 출력
sql> SELECT ename || ' ' || 'is a' || ' ' || job AS "employees Details“ FROM emp
EMP 테이블에서 ename과 job을 “KING is a PRESIDENT” 형식으로 출력
Distinct
- 특별히 명시되지 않았다면, SQL*Plus는 중복되지는 행을 제거하지 않고 Query 결과를 출력
- 결과에서 중복되는 행을 제거하기 위해서는 SELECT 키워드 바로 뒤에 DISTINCT를 기술
- DISTINCT라는 키워드는 항상 SELECT 바로 다음에 기술
- DISTINCT뒤에 나타나는 칼럼들은 모두 DISTINCT의 영향을 받음
- DISTINCT뒤에 여러 개의 칼럼을 기술하였을 때 나타나는 행은 칼럼의 조합들이 중복되지 않게 출력
- DISTINCT를 사용하여 나타나는 결과는 기본적으로 오름차순 정렬
- EMP 테이블에서 JOB을 모두 출력
- Select job from emp;
e.g.
sql> select distinct job from emp;
EMP 테이블에서 JOB을 중복을 제거하고 출력
sql> SELECT DISTINCT deptno, job FROM emp
EMP 테이블에서 deptno별로 job를 한번씩 출력
-- oracle에서 concat는 두 개 항목만 가능
select concat(ename,sal) from emp;
select ename||'('||sal||')' from emp;
select ename||'s salary is '||sal from emp;
-- ename과 salary를 "KING: 1 Year salary = 6000" 형식으로 출력
select ename||': 1 Year salaray = '||sal*12 from emp;
select job from emp;
-- distinct는 중복이 있는 경우 한번만 출력
select distinct job from emp;
-- 연습문제
-- 1. EMP 테이블의 구조 조회
desc emp;
-- 2. EMP 테이블의 모든 내용을 조회
select * from emp;
-- 3. EMP 테이블에서 중복되지 않는 deptno를 출력
select distinct deptno from emp;
-- 4. EMP 테이블의 ename과 job를 연결하여 출력
select ename||'('||job||')' from emp; -- select concat(ename,job) from emp;
-- 5. DEPT 테이블의 deptno과 loc를 연결하여 출력
select concat(deptno,loc) from dept;
-- 6. EMP 테이블의 job과 sal를 연결하여 출력
select job||sal from emp;
-- 7. 사원테이블에서 직원들의 연봉(급여 * 12) “연 봉”으로 계산하여 사원명, 급여, 연봉 출력
select ename, sal, sal*12 "연 봉" from emp;
-- 8. '(직원이름)의 업무는 (직업)이고 급여는 (급여)만원입니다' 형식으로 출력
select ename||'의 업무는 '||job||'이고 급여는 '||sal||'만원입니다' from emp;
특정 행 검색
1. 일반적인경우테이블에있는모든자료를조회할필요없이사용자가원하는 자료를 조회하는 경우가 대부분 입니다. 이러한 질의를 만족하게 하는 것이 WHERE절입니다. WHERE절은 수행될 조건 절을 포함하며 FROM절 바로 다음에 기술됩니다.
2. Syntax
SELECT [DISTINCT] {*, column [alias], . . .}
FROM table_name
[WHERE condition]
[ORDER BY {column, expression} [ASC | DESC]];
- 1) DISTINCT 중복 행 제거 옵션
- 2) * 테이블의 모든 column 출력
- 3) alias 해당 column에 대한 다른 이름 부여
- 4) table_name 테이블명 질의 대상 테이블 이름
- 5) WHERE 조건을 맊족하는 행들맊 검색
- 6) condition column명, 표현식, 문자 상수, 숫자 상수, 비교 연산자로 구성된다.
- 7) ORDER BY 질의 결과 정렬을 위한 옵션(ASC:오름차순(Default),DESC내림차순)
e.g.
EMP 테이블에서 hiredate가 1982년 01월 01일 이후 인 사원의 empno,ename,job,sal,hiredate,deptno 을 출력
날짜 - to_date('2008/04/14 22:02:14', 'yyyy/mm/dd hh24:mi:ss') „08/04/14‟
오늘 날짜 및 시갂 - sysdate
select empno,ename,job,sal,hiredate,deptno from emp
where hiredate >= to_date('1982/01/01', 'yyyy/mm/dd') hiredate >= „82/01/01‟
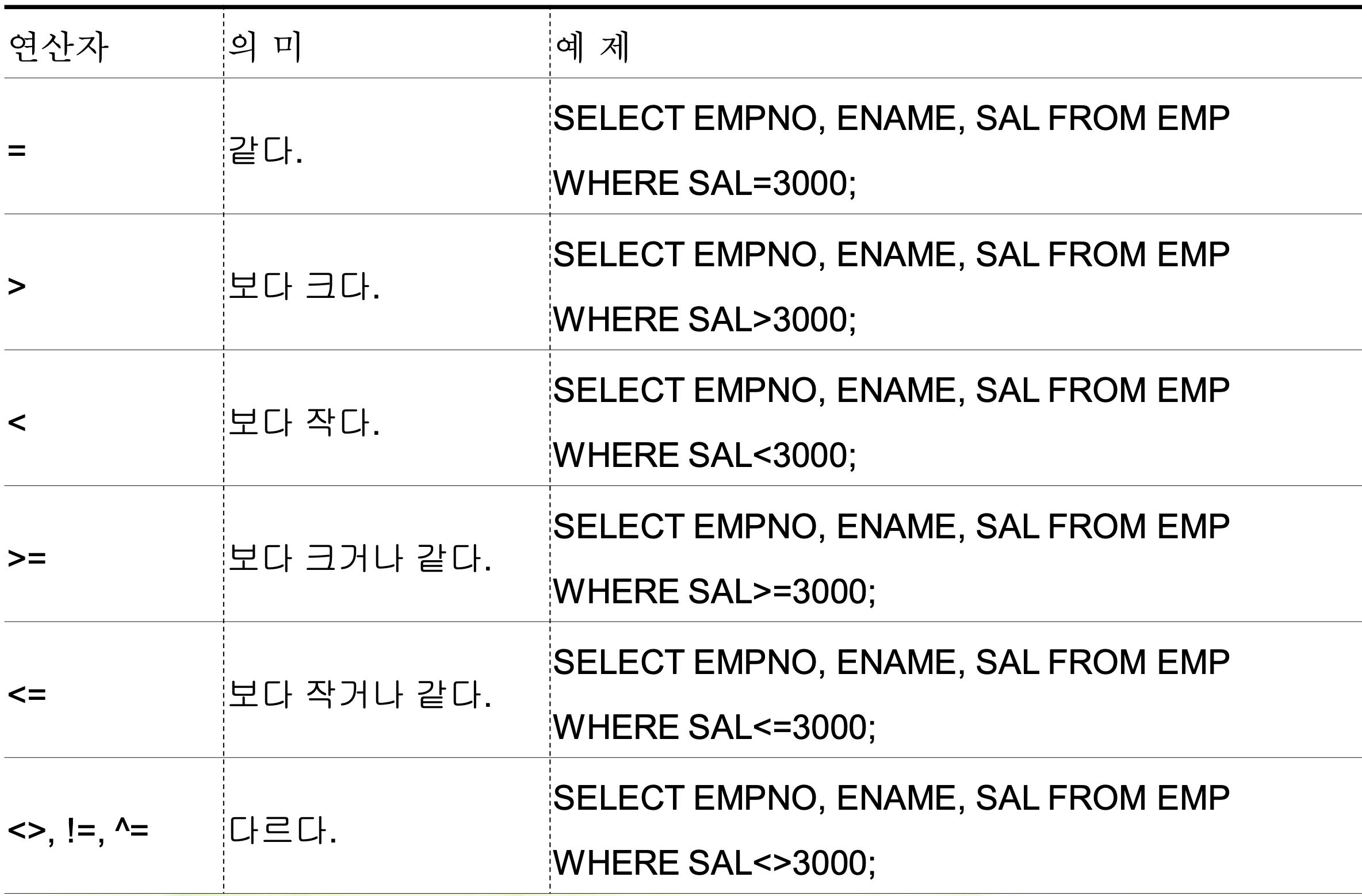
SQL연산자
연산자 설명
BETWEEN a AND b a와b사이에 있다.(a, b값 포함)
IN (list) list의 값 중 어느 하나와 일치한다.
LIKE 문자 형태와 일치한다.(%,_사용)
IS NULL NULL값을 가졌다.
NOT BETWEEN a AND b a와b사이에 있지않다.(a, b값 포함하지 않음)
NOT IN (list) list의 값과 일치하지 않는다..
NOT LIKE 문자 형태와 일치하지 않는다.
NOT IS NULL NULL값을 갖지 않는다.
BETWEEN연산자: 두 값의 범위에 해당하는 행을 출력하기 위해 사용
작은 값을 앞에 기술하고 큰 값은 뒤에 기술
e.g.
Between A and B
Use the BETWEEN operator to display rows based on a range of values.
SELECT empno,ename,job,sal,hiredate,deptno FROM emp
where hiredate between „82/01/01‟ and „82/12/31‟;EMP 테이블에서 hiredate가 1982년인 사원의 empno,ename,job,sal,hiredate,deptno 를 출력
in( A, B, ...etc.)
IN 연산자: 목록에 있는 값에 대해서 출력하기 위해 IN연산자를 사용
SELECT empno,ename,job,sal,hiredate FROM emp WHERE empno IN (7902,7788,7566)EMP 테이블에서 empno가 7902,7788,7566인 사원의 empno,ename,job,sal,hiredate 를 출력
Like '%A%'
String 값의 비교에서 wildcard 를 사용할 수 있다.
% (percent character)는 문자가 없거나 string을 의미한다.
1) (underscore character)는 한 문자를 의미한다.
2) name에 값이 X_Y가 포함되어 있는 문자열을 조회하고자 할 경우 Escape를 사용
3) WHERE name LIKE ‘%X\_Y%’ ESCAPE ‘\’;
이름이 w로 시작하는
SELECT empno, ename, mgr, sal FROM emp
WHERE ename Like ‘W%’;이름이 N로 끝나는
SELECT empno, ename, mgr, sal FROM emp
WHERE ename Like ‘%N’;이름 두번째 글자에 A가 들어가는
SELECT empno, ename, mgr, sal FROM emp
WHERE ename Like ‘_A%’;
e.g.
SELECT empno,ename,job,sal,hiredate,deptno FROM emp where hiredate LIKE '82%„EMP 테이블에서 hiredate가 1982년인 사원의 empno,ename,job,sal,hiredate,deptno 를 출력
연산자 우선순위
| Order Evaluated | Operator | |
| 1 | All Comparison Operators ( >, <, >=, >=, == ) | |
| 2 | NOT | |
| 3 | AND | |
| 4 | OR | |
Override rules of precedence by using parentheses().
select ename, sal from emp where sal>=2000 and sal<=3000;
-- column between A and B : A 보다 크거나 같고 B 보다 작거나 같다
select ename, sal from emp where sal between 2000 and 3000;
select ename, sal from emp where sal between 3000 and 2000; -- doesn't work
select ename, sal from emp where sal not between 2000 and 3000;
-- =는 제외
select ename, sal from emp where sal<2000 or sal>3000;
-- 이름이 K나 S로 시작하는 사람 / S만 쓰면 smith가 포함 안 됨 / s<sc / 앞에 한 글자씩 비교해서 같으면 다음 글자
select ename from emp where ename between 'K' and 'SZZ';
-- 10번 또는 20번에 근무하는 사람
select ename, deptno from emp where deptno=10 or deptno=20;
select ename, deptno from emp where deptno in(10,20);
select ename, deptno from emp where deptno not in(10,20);
select empno, ename, hiredate, sal from emp
where sal between 1500 and 3000;
select ename, sal, hiredate, comm from emp
where comm is not null and sal between 2000 and 3500;
select ename, sal, comm from emp where comm is null or
sal not between 2000 and 4000;
select empno, ename, job from emp
where job in ('SALESMAN', 'CLERK', 'ANALYST');
select empno, ename, deptno from emp where deptno in (10, 30);
select empno, ename, job from emp
where job not in ('MANAGER', 'CLERK');
select empno, ename, hiredate from emp
where hiredate between '81/01/01' and '81/12/31';
select ename from emp where ename between 'D' and 'TZZZ';
select ename, sal, comm, (sal+nvl(comm,0))*12 "Annual salary" from emp
where sal between 1000 and 3000;
select ename||'('||job||')'||'은 급여가 '||sal||'이고
연봉은 '||(sal+coalesce(sal+comm,sal))*12||'이다' from emp;
select ename||' makes $'||sal||' monthly, $'||
(sal+coalesce(sal+comm,sal))*12||' annually ' from emp;
Order by
- 질의 결과에 RETURN되는 행의 순서는 정의되지 않습니다.
- ORDER BY젃은 행을 정렬하는데 사용할 수 있습니다.
- ORDER BY젃 사용하는 경우 SELECT문의 맨 뒤에 기술되어야 합니다.
- 정렬을 위한 표현식이나 Alias을 명시할 수 있습니다.
- Syntax
SELECT [DISTINCT] {*, column [alias], . . .}
FROM table_name
[WHERE condition]
[ORDER BY {column, expression} [ASC | DESC]];
ORDER BY 검색된 행이 출력되는 순서를 명시합니다.
ASC 행의 오름차순 정렬(Default)
DESC 행의 내림차순 정렬 - 디폴트 정렬은 오름차순입니다
- 숫자값은가장적은값이먼저출력됩니다.(예:1~999)
- 날짜 값은 가장 빠른 값이 먼저 출력됩니다.(예 : 01-JAN-92 ~ 01-JAN-95)
- 문자값은알파벳순서로출력됩니다.(예:A~Z~a~z)
- Null값은 오름차순에서는 제일 나중에 그리고 내림차순에서는 제일 먼저 옵니다.
- 행이 디스플레이 되는 순서를 바꾸기 위해서, ORDER BY젃에서 열 이름 뒤에 DESC키워 드를 명시해야 합니다.
e.g.
SELECT hiredate,empno,ename,job,sal,deptno FROM emp ORDER BY hiredateemp 테이블에서 hiredate의 오름차순으로 hiredate,empno,ename,job,sal,deptno를 출력
SELECT hiredate,empno,ename,job,sal,deptno FROM emp ORDER BY hiredate descemp 테이블에서 hiredate의 내림차순으로 hiredate,empno,ename,job,sal,deptno 를 출력
Order By
1. 다양한정렬방법
SQL> SELECT empno,ename,job,sal,sal*12 annsal FROM emp ORDER BY annsal;
SQL> SELECT empno,ename,job,sal,sal*12 annsal FROM emp ORDER BY sal*12;
SQL> SELECT empno,ename,job,sal,sal*12 annsal FROM emp ORDER BY 5;
2. 하나이상의 열로 질의 결과를 정렬할 수 있습니다.
3. 주어진 테이블에 있는 개수까지만 가능합니다.
4. ORDER BY절에서 열을 명시하고, 열 이름은 콤마로 구분합니다.
5. 열의 순서를 바꾸고자 한다면 열 이름 뒤에 DESC를 명시합니다.
6. SELECT절에 포함되지 않는 열로 정렬할 수도 있습니다.
e.g.
SELECT deptno,sal,empno,ename,job FROM emp ORDER BY deptno, sal DESCemp 테이블에서 deptno의 오름차순으로 정렬하고 같은 경우 sal의 내림차순으로 deptno,sal,empno,ename,job 를 출력
SELECT deptno,job,sal,empno,ename,hiredate FROM emp ORDER BY deptno,job,sal DESCemp 테이블에서 deptno의 오름차순으로 정렬하고 같은 경우 job의 오름차순으 로 job이 같은 경우에는 sal의 내림차순으로 deptno,job,sal,empno,ename,hiredate를 출력
EX
- EMP 테이블에서 sal이 3000이상인 사원의 empno, ename, job, sal을 출력하는 SELECT 문 장을 작성
- EMP 테이블에서 empno가 7788인 사원의 ename과 deptno를 출력하는 SELECT 문장
- EMP 테이블에서 hiredate가 1981년 2월 20과 1981년 5월 1일 사이에 입사한 사원의 ename,job,hiredate을 출력하는 SELECT 문장을 작성(단 hiredate 순으로 출력)
- EMP 테이블에서 deptno가 10,20인 사원의 모든 정보를 출력하는 SELECT 문장을 작성(단 ename순으로 정렬)
- EMP 테이블에서 sal이 1500이상이고 deptno가 10,30인 사원의 ename과 sal를 출력하는 SELECT 문장을 작성(단 HEADING을 employee과 Monthly Salary로 출력)
- EMP 테이블에서 hiredate가 1982년인 사원의 모든 정보를 출력하는 SELECT 문을 작성
계층구조 쿼리란?
오라클 데이터베이스 scott 유저의 emp 테이블을 보면 empno와 mgr컬럼이 있으며, mgr 컬럼 데이터는 해당 사원의 관리자의 empno를 의미 한다.
예를 들어서 아래의 데이터를 보면
|
1
2
3
4
|
EMPNO ENAME SAL MGR
------ ------- ------ ------
7369 SMITH 800 7902
7902 FORD 3000 7566
|
- - empno 7369사원의 관리자는 7902의 empno를 가진 사원이며
- - empno 7902사원의 관리자는 7566의 empno를 가진 사원이다.
이런 상위 계층과 하위계층의 관계를 오라클에서는 START WITH와 CONNECT BY를 이용해서 쉽게 조회 할 수 있다.
계층구조 쿼리 Synctax
START WITH
- - 계층 질의의 루트(부모행)로 사용될 행을 지정 한다.
- - 서브쿼리를 사용할 수도 있다.
CONNECT BY
- - 이 절을 이용하여 계층 질의에서 상위계층(부모행)과 하위계층(자식행)의 관계를 규정 할 수 있다.
- - PRIOR 연산자와 함께 사용하여 계층구조로 표현할 수 있다.
- - CONNECT BY PRIOR 자식컬럼 = 부모컬럼 : 부모에서 자식으로 트리구성 (Top Down)
- - CONNECT BY PRIOR 부모컬럼 = 자식컬럼 : 자식에서 부모로 트리 구성 (Bottom Up)
- - CONNECT BY NOCYCLE PRIOR : NOCYCLE 파라미터를 이용하여 무한루프 방지
- - 서브쿼리를 사용할 수 없다.
LEVEL Pseudocolumn
- - LEVEL은 계층구조 쿼리에서 수행결과의 Depth를 표현하는 의사컬럼이다.
ORDER SIBLINGS BY
- - ORDER SIBLINGS BY절을 사용하면 계층구조 쿼리에서 편하게 정렬작업을 할 수 있다.
CONNECT BY의 실행순서는 다음과 같다.
- - 첫째 START WITH 절
- - 둘째 CONNECT BY 절
- - 세째 WHERE 절 순서로 풀리게 되어있다.
계층구조 쿼리 예제
간단예제
아래는 직업이 PRESIDENT을 기준으로 계층 구조로 조회하는 예이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- LEVEL컬럼으로 depth를 알수 있다.
-- JONES의 관리자는 KING 이며, SCOTT의 관리자는 JONES 이다.
-- 상/하의 계층 구조를 쉽게 조회 할 수 있다.
SELECT LEVEL, empno, ename, mgr
FROM emp
START WITH job = 'PRESIDENT'
CONNECT BY PRIOR empno = mgr;
LEVEL EMPNO ENAME MGR
------ -------- -------- -------
1 7839 KING
2 7566 JONES 7839
3 7788 SCOTT 7566
4 7876 ADAMS 7788
3 7902 FORD 7566
4 7369 SMITH 7902
...
|
LEVEL의 활용
LEVEL Pseudocolumn을 이용하면 계층구조 쿼리를 좀 더 다양하게 활용 할 수 있다.
아래는 LEVEL의 배율만큼 공백을 왼쪽에 추가하여 계층구조를 한눈에 볼 수 있게 표현한 예이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
-- SQL*Plus에서만 깔끔하게 보기위해서
COL ename FORMAT A20;
-- 왼쪽에 LEVEL만큼 공백을 추가하여 계층구조로 조회하는 예제
SELECT LEVEL, LPAD(' ', 4*(LEVEL-1)) || ename ename, empno, mgr, job
FROM emp
START WITH job='PRESIDENT'
CONNECT BY PRIOR empno=mgr;
LEVEL ENAME EMPNO MGR JOB
------ -------------------- ------- ----- --------
1 KING 7839 PRESIDEN
2 JONES 7566 7839 MANAGER
3 SCOTT 7788 7566 ANALYST
4 ADAMS 7876 7788 CLERK
3 FORD 7902 7566 ANALYST
4 SMITH 7369 7902 CLERK
2 BLAKE 7698 7839 MANAGER
...
|
아래는 LEVEL별로 급여 합계와 사원수를 조회하는 예제이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
-- LEVEL별로 급여 합계와 사원수를 조회하는 예제
SELECT LEVEL, AVG(sal) total, COUNT(empno) cnt
FROM emp
START WITH job='PRESIDENT'
CONNECT BY PRIOR empno=mgr
GROUP BY LEVEL
ORDER BY LEVEL;
LEVEL TOTAL CNT
-------- ---------- ----------
1 5000 1
2 8275 3
3 13850 8
4 1900 2
|
PRIOR의 활용
PRIOR연산자를 SELECT 절에서 사용해보자.
아래는 사원의 관리자를 PRIOR연산자를 이용해서 조회하는 예제이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
-- SQL*Plus에서만 깔끔하게 보기위해서
COL mgrname FORMAT A10;
-- SELECT절에 "PRIOR ename mgrname"을 확인해 보자
SELECT LEVEL, LPAD(' ', 4*(LEVEL-1)) || ename ename,
PRIOR ename mgrname,
empno, mgr, job
FROM emp
START WITH job='PRESIDENT'
CONNECT BY PRIOR empno=mgr;
LEVEL ENAME MGRNAME EMPNO MGR JOB
------- -------------------- ---------- ---------- ---------- ---------
1 KING 7839 PRESIDENT
2 JONES KING 7566 7839 MANAGER
3 SCOTT JONES 7788 7566 ANALYST
4 ADAMS SCOTT 7876 7788 CLERK
3 FORD JONES 7902 7566 ANALYST
2 BLAKE KING 7698 7839 MANAGER
3 MARTIN BLAKE 7654 7698 SALESMAN
3 TURNER BLAKE 7844 7698 SALESMAN
3 JAMES BLAKE 7900 7698 CLERK
2 CLARK KING 7782 7839 MANAGER
3 MILLER CLARK 7934 7782 CLERK
|
Bottom Up 조회 예제
위 간단 예제를 역순(자식에서 부모로 트리 구성, Bottom Up)으로 조회 해 보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- SQL*Plus에서만 깔끔하게 보기위해서
COL ename FORMAT A20;
-- ename을 기준으로 Bottom Up으로 조회하는 예제이다.
SELECT LEVEL, LPAD(' ', 4*(LEVEL-1)) || ename ename, empno, mgr, job
FROM emp
START WITH ename='SMITH' -- 최 하위 노드 값이 와야 한다.
CONNECT BY PRIOR mgr = empno;
LEVEL ENAME EMPNO MGR JOB
------ --------------- -------- -------- ---------
1 SMITH 7369 7902 CLERK
2 FORD 7902 7566 ANALYST
3 JONES 7566 7839 MANAGER
4 KING 7839 PRESIDENT
|
- - 순방향(Top Down-상위~하위) : PRIOR 하위 = 상위
- - 역방향(Bottom Up-하위~상위) : PRIOR 상위 = 하위
http://www.gurubee.net/lecture/1300
계층구조 쿼리(Hierarchical Queries)란?
계층구조 쿼리란? 오라클 데이터베이스 scott 유저의 emp 테이블을 보면 empno와 mgr컬럼이 있으며, mgr 컬럼 데이터는 해당 사원의 관리자의 empno..
www.gurubee.net